
Pod 生命周期
Pod 的 status 定义在 PodStatus 对象中,其中有一个 phase 字段。它简单描述了 Pod 在其生命周期的阶段。熟悉Pod的各种状态对我们理解如何设置Pod的调度策略、重启策略是很有必要的。
下面是 phase 可能的值:
| 阶段 | 描述 |
|---|---|
| Pending | Pod 已被 Kubernetes 系统接受,但有一个或者多个容器镜像尚未创建。等待时间包括调度 Pod 的时间和通过网络下载镜像的时间,这可能需要花点时间。 |
| Running | 该 Pod 已经绑定到了一个节点上,Pod 中所有的容器都已被创建。至少有一个容器正在运行,或者正处于启动或重启状态。 |
| Succeeded | Pod 中的所有容器都被成功终止,并且不会再重启。 |
| Failed | Pod 中的所有容器都已终止了,并且至少有一个容器是因为失败终止。也就是说,容器以非0状态退出或者被系统终止。 |
| Unknown | 因为某些原因无法取得 Pod 的状态,通常是因为与 Pod 所在主机通信失败。 |
Pod 状态
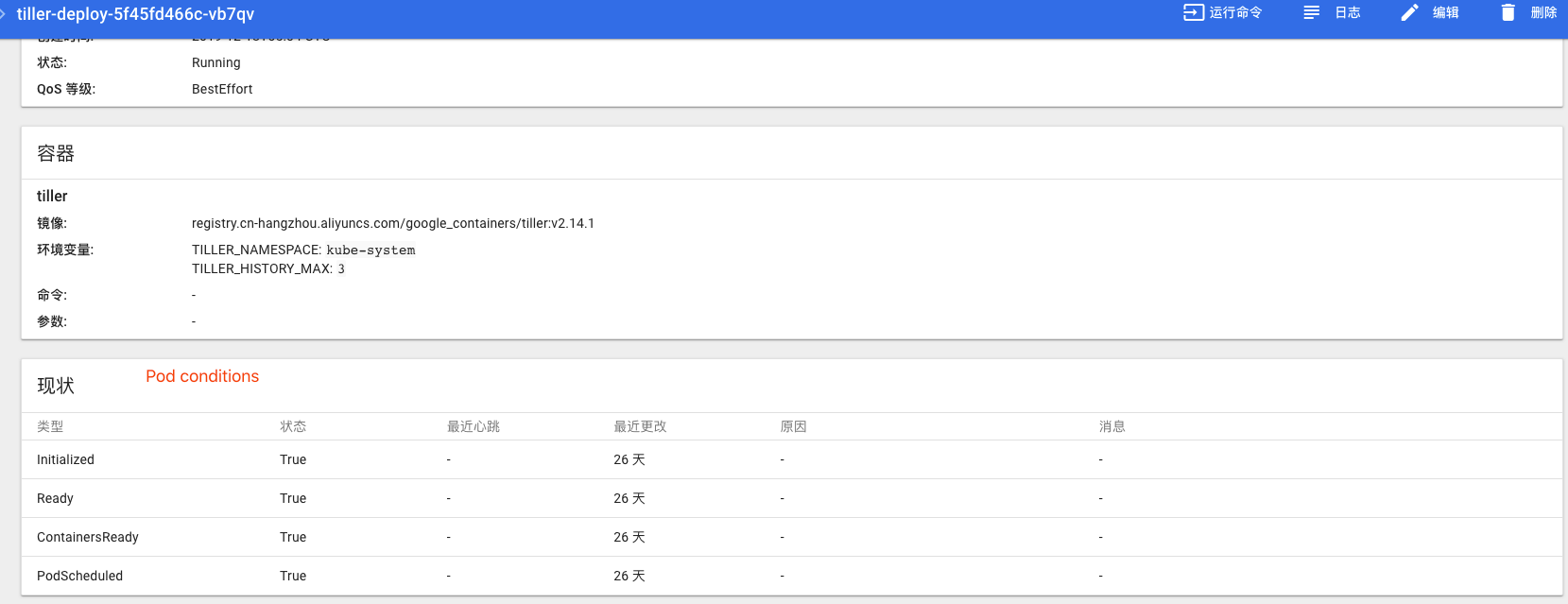
Pod 有一个 PodStatus 对象,其中包含一个 PodCondition 数组,代表 Condition 是否通过。
PodCondition 属性描述:
| 字段 | 描述 |
|---|---|
| lastProbeTime | 最后一次探测 Pod Condition 的时间戳。 |
| lastTransitionTime | 上次 Condition 从一种状态转换到另一种状态的时间。 |
| message | 上次 Condition 状态转换的详细描述。 |
| reason | Condition 最后一次转换的原因。 |
| status | Condition 状态类型,可以为 True False Unknown |
| type | Condition 类型 |
Condition Type 的描述:
| Type | 描述 |
|---|---|
| PodScheduled | Pod 已被调度到一个节点 |
| Ready | Pod 能够提供请求,应该被添加到负载均衡池中以提供服务 |
| Initialized | 所有 init containers 成功启动 |
| Unschedulable | 调度器不能正常调度容器,例如缺乏资源或其他限制 |
| ContainersReady | Pod 中所有容器全部就绪 |
Pod 重启策略
Pod的重启策略(RestartPolicy)应用于Pod内的所有容器,并且仅在Pod所处的Node上由kubelet进行判断和重启操作。当某个容器异常退出或者健康检查失败时,kubelet将根据 RestartPolicy 的设置来进行相应的操作。
Pod的重启策略包括 Always、OnFailure和Never,默认值为Always。
Always:当容器失败时,由kubelet自动重启该容器。OnFailure:当容器终止运行且退出码不为0时,有kubelet自动重启该容器。Never:不论容器运行状态如何,kubelet都不会重启该容器。
失败的容器由 kubelet 以五分钟为上限的指数退避延迟(10秒,20秒,40秒…)重新启动,并在成功执行十分钟后重置。
Pod 容器探针
探针 是由 kubelet 对容器执行的定期诊断。要执行诊断,kubelet 调用由容器实现的 Handler。有三种类型的处理程序:
ExecAction:在容器内执行指定命令。如果命令退出时返回码为 0 则认为诊断成功。TCPSocketAction:对指定端口上的容器的 IP 地址进行 TCP 检查。如果端口打开,则诊断被认为是成功的。HTTPGetAction:对指定的端口和路径上的容器的 IP 地址执行 HTTP Get 请求。如果响应的状态码大于等于200 且小于 400,则诊断被认为是成功的。
每次探测都将获得以下三种结果之一:
Success:容器诊断通过Failure:容器诊断失败Unknown:诊断失败,因此不应采取任何措施
Kubelet 可以选择是否执行在容器上运行的两种探针执行和做出反应:
livenessProbe:指示容器是否正在运行。如果存活探测失败,则 kubelet 会杀死容器,并且容器将受到其 重启策略 的影响。如果容器不提供存活探针,则默认状态为Success。readinessProbe:指示容器是否准备好服务请求。如果就绪探测失败,端点控制器将从与 Pod 匹配的所有 Service 的端点中删除该 Pod 的 IP 地址。初始延迟之前的就绪状态默认为Failure。如果容器不提供就绪探针,则默认状态为Success。
示例:
ExecAction:
1 | apiVersion: apps/v1 |
TCPSocketAction:
1 | apiVersion: v1 |
HTTPGetAction:
1 | apiVersion: apps/v1 |
Pod 的生命
一般来说,Pod 不会消失,直到人为销毁他们。这可能是一个人或控制器。这个规则的唯一例外是成功或失败的 phase 超过一段时间(由主服务器中的 terminate-pod-gc-threshold 确定)的Pod将过期并被自动销毁。
三种可用的控制器类型:
Job:例如批量计算,仅适用于restartPolicy为OnFailure或Never的 PodReplicationController,ReplicaSet, 或Deployment:例如 Web 服务,ReplicationControllers 仅适用于restartPolicy为Always的 Pod。DaemonSet:需要在每个节点运行一个的 Pod,以便用于系统服务。
所有这三种类型的控制器都包含一个 PodTemplate。建议创建适当的控制器,让它们来创建 Pod,而不是直接自己创建 Pod。这是因为单独的 Pod 在机器故障的情况下没有办法自动复原,而控制器却可以。
如果节点死亡或与集群的其余部分断开连接,则 Kubernetes 将应用一个策略将丢失节点上的所有 Pod 的 phase 设置为 Failed。
参考链接
- https://kubernetes.io/zh/docs/concepts/workloads/pods/pod-lifecycle/
- https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.17/#podstatus-v1-core
- https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.17/#podcondition-v1-core
- https://www.jianshu.com/p/91625e7a8259
- https://www.jianshu.com/p/68670bef1c3f
---本文结束感谢您的阅读。微信扫描二维码,关注我的公众号---

本文链接: https://www.yp14.cn/2020/01/13/Kubernetes-Pod-生命周期/
版权声明: 本作品采用 知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议 进行许可。转载请注明出处!

